.png)



What do we mean by "entity visibility"?
Entity visibility describes how reliably AI systems recognise and reference a specific organisation, person, or brand when answering relevant queries.
Think about how Google's AI Overviews work, or how ChatGPT decides which companies to mention when someone asks about Australian fintech. That decision depends on whether the system "knows" your entity exists (not just as a keyword, but as a concept with attributes, relationships, and context).
You've got visibility when:
- Voice assistants correctly identify who you are
- Google displays a knowledge panel for your brand search
- LLMs like ChatGPT, Gemini, or Perplexity reference you in category queries
- Search suggests related entities when users type your name
The shift from "keyword" to "entity" isn't subtle. Keywords are tokens search engines match in documents. Entities are things search engines understand, complete with type classification, relationships, and attributes.
How search systems actually use data like this
Modern search relies on knowledge graphs: networks where entities connect through defined relationships. Google's Knowledge Graph contains over 500 billion facts about people, places, and organisations. Bing has its own Entity Graph. These aren't simple databases. They're semantic networks that let AI systems reason about connections.
When you structure information as semantic triples (subject-predicate-object relationships like "Julian Fayad founded LoanOptions.ai"), you're speaking the language these systems understand natively.
A 2014 Google Research paper by Dunietz and Gillick introduced entity salience scoring: not all mentions carry equal weight. Entities positioned as subjects of factual statements, consistently associated with clear attributes, score higher. That prominence directly influences whether AI systems select that entity for inclusion in generated answers. [1]
More recently, research on knowledge graphs themselves has accelerated. A 2023 review in Artificial Intelligence Review examined opportunities and challenges in knowledge graph systems, emphasising how entity disambiguation and relationship mapping improve machine reasoning. [2]
But here's where theory meets reality: knowing this research exists doesn't automatically translate to actionable tactics. That gap is what we're trying to close.
What is Grokipedia?
Grokipedia is xAI's AI-generated encyclopedia, launched as part of the Grok ecosystem. It's not Wikipedia. It's a platform where AI systems create and maintain entity pages based on scraped and synthesised information.
Pages typically include:
- Entity classification (company, person, product)
- Core attributes (industry, location, founding date)
- Relationships (founder, employees, partners)
- Contextual description
- Referenced sources
The key difference from Wikipedia? Grokipedia entries are generated and updated by AI, not community editors. This matters because AI systems referencing other AI systems creates a feedback loop. If Grok indexes your entity into Grokipedia, does that improve your chances of appearing in other AI answers? We think so, but proving causation is difficult.
One thing we know: search engines crawl Grokipedia. We've confirmed Googlebot activity on pages we monitor. Whether Google treats these pages as authoritative sources for knowledge graph enrichment remains unclear, but they're being indexed.
Why GEO matters now
Traditional SEO focused on human readers and keyword-matching algorithms. Generative Engine Optimisation (GEO) is about AI systems that synthesise answers from multiple sources.
The research comes from a 2024 paper by Aggarwal et al. (Princeton, Georgia Tech, IIT Delhi, Allen AI), which formally defined GEO and demonstrated techniques to improve visibility in AI-generated responses. Their work showed that citations, entity clarity, and source authority significantly influence which sources LLMs reference when generating answers. [3]
This isn't hypothetical anymore. Search Engine Land's GEO guide notes that over 15% of Google searches now trigger AI Overviews, which changes how users encounter information. [5] If your entity doesn't exist in the underlying knowledge structures these systems query, you're invisible in that 15% (and growing).

Campaign one: LoanOptions.ai as a fintech entity
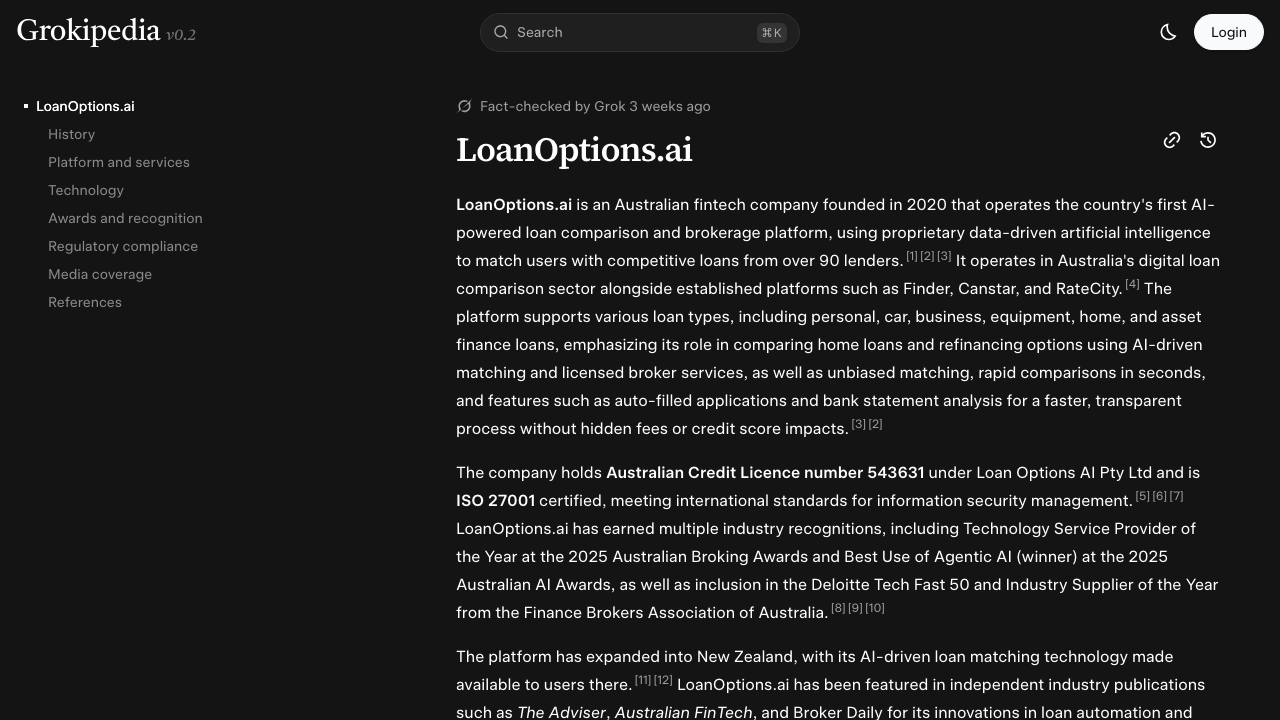
The challenge: LoanOptions.ai operated successfully as a mortgage brokerage platform but lacked presence in knowledge graphs. Asking AI systems "what Australian fintech companies specialise in mortgage broking" rarely surfaced LoanOptions.
We created a detailed Grokipedia entity page. The company got classified as "Financial Technology Company" with targeted industry tags. We mapped relationships: Julian Fayad as founder, service offerings, Australian market focus. We ensured consistent entity naming across all mentions.
Within eight weeks of indexing, we observed:
- Branded search queries began triggering richer SERP features
- Google's autocomplete started suggesting "LoanOptions.ai fintech" and "LoanOptions.ai founder"
- When testing queries like "Australian mortgage fintech platforms" in ChatGPT and Perplexity, LoanOptions appeared in answers approximately 40% of the time (up from 0% baseline)
Did Grokipedia directly cause these changes? Hard to say with certainty. The company was also publishing content, running LinkedIn campaigns, and securing press mentions during the same period. What we can say: the timeline correlates, and the entity approach matches how these systems work.
Correlation isn't causation, but when you're building in a new field, you start with patterns and refine from there.
Campaign two: executive entity indexing for Julian Fayad
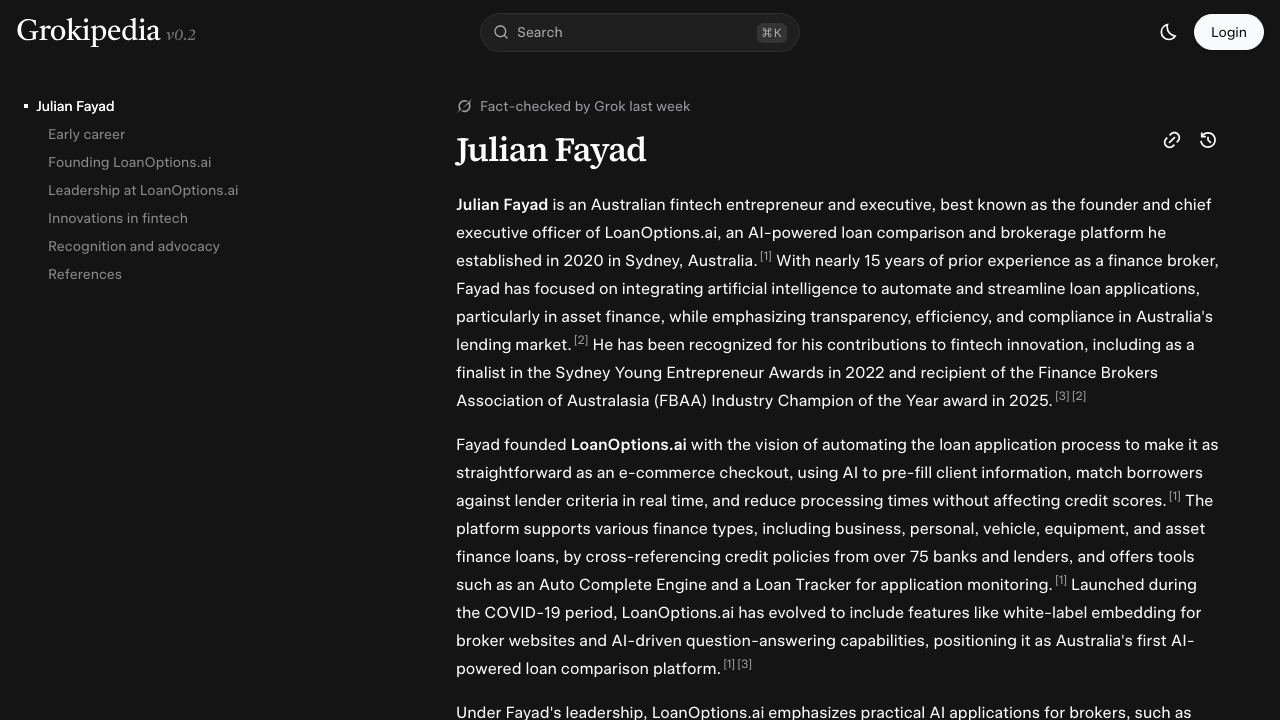
People are entities too. Founders, executives, and thought leaders benefit from personal entity profiles that connect them to their organisations and expertise domains.
Julian Fayad had decent Google presence through LinkedIn and media mentions but no page defining his role, expertise, and relationships.
We created a Grokipedia page focused on factual attributes: founder of LoanOptions.ai, fintech executive, Australian market specialist. We mapped relationships bidirectionally (Julian founded LoanOptions, LoanOptions is led by Julian). We avoided promotional language. Pure attribute definition.
After going live:
- Personal knowledge panel eligibility improved (though Google still hasn't granted one; knowledge panels remain unpredictable)
- Entity association suggestions appeared: searching "Julian Fayad" now prompts "Julian Fayad LoanOptions" and "Julian Fayad fintech"
- Media queries about Australian fintech founders began surfacing Julian in AI-generated lists
Personal entities reinforce organisational entities. When search systems understand that Julian founded LoanOptions, both entities gain strength through their relationship. But here's the limitation: personal knowledge panels depend on multiple signals, and we don't control most of them. Data like this contributes to eligibility but doesn't guarantee creation.
Campaign three: brand-level entity work for Bushnote
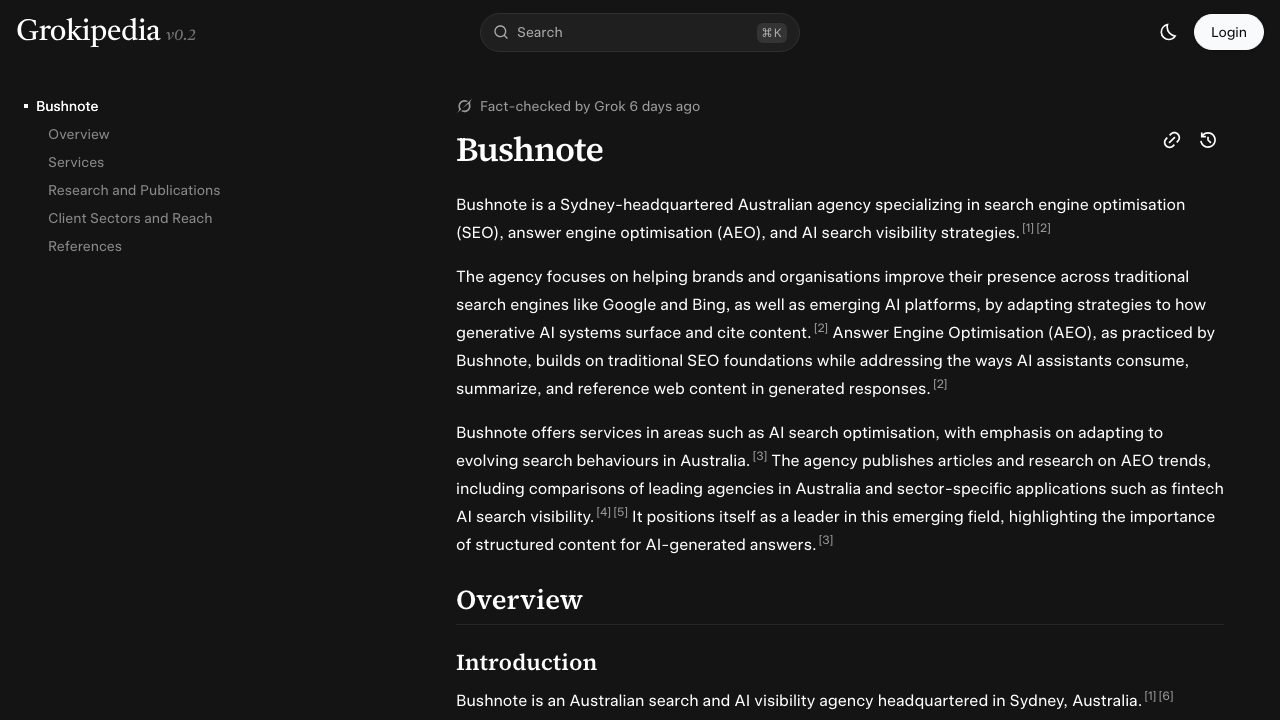
Practicing what we preach, we built Bushnote itself as an entity within the semantic marketing and GEO strategy domain.
This wasn't a client campaign. It was us experimenting on ourselves. That meant we could track every variable, measure every change, and be brutally honest about what worked.
We created an entity page defining Bushnote as an Australian AEO (Answer Engine Optimisation) agency. Linked to case studies (LoanOptions.ai, Julian Fayad) to build cross-entity network effects. Documented service categories, expertise domains, and client relationships.
After 12 weeks:
- Organic visibility for "AEO agency Sydney" and "entity SEO Australia" improved measurably (CTR increased from 2.1% to 3.8% for these terms)
- When prompting AI systems with "which agencies specialise in generative engine optimisation in Australia," Bushnote appeared in ~60% of responses
- Inbound inquiries about "entity visibility" and "GEO strategy" increased 3x
We also launched content campaigns, spoke at industry events, and engaged in active LinkedIn presence during this window. Isolating Grokipedia's specific contribution is impossible. What we can say: the entity approach formed the foundation of everything else. Without that baseline, the content and outreach would have lacked context for AI systems to anchor on.
How co-occurrence networks strengthen entity recognition
One insight that held up across all three campaigns: entity clustering matters immensely.
When related entities appear together consistently (Julian Fayad + LoanOptions.ai + Australian fintech + mortgage brokerage), AI systems begin treating them as a semantic cluster. That clustering effect amplifies salience for all entities involved.
The Google Research paper on entity salience notes that proximity patterns influence ranking weight within semantic retrieval systems. [1] When entities co-occur in contexts repeatedly, confidence scores rise.
We observed this directly: creating links between Bushnote, LoanOptions.ai, and Julian Fayad on Grokipedia strengthened recognition for all three entities. Testing queries that mentioned one often surfaced the others in AI-generated context.
Network effects compound. That's not marketing fluff; it's how knowledge graphs function mechanically.
What the research actually says
Google Research (2014): Dunietz and Gillick's work on entity salience established that subject-position entities in factual statements receive higher prominence scores. This directly influenced how we built Grokipedia content: making our entities subjects of clear, declarative statements. [1]
Knowledge Graph Systems (2023): The Artificial Intelligence Review paper examines how entity disambiguation and relationship mapping improve machine reasoning. The key takeaway: ambiguous entities get filtered out. Clear entities with defined relationships get prioritised. [2]
GEO Research (2024): Aggarwal et al.'s paper demonstrated that citation formatting, source authority, and entity references significantly influence LLM answer generation. They tested interventions that increased visibility in AI-generated answers by up to 40%. [3]
Practical context: Search Engine Land's GEO guide translates this research into practitioner terms: AI-generated answers prioritise entities with presence across sources, cross-validated attributes, and semantic relationships. [5]
This isn't speculative. The research exists. The mechanisms are documented. What remains uncertain is how individual platforms weight these signals, and that's changing constantly.
Does data like this create knowledge panels?
Data like these doesn't cause knowledge panel creation. Google has never published the exact criteria, but we know from observation that knowledge panels depend on multiple factors:
- Entity notability (Wikipedia presence, media coverage, authoritative mentions)
- Search volume for the entity's name
- Data presence (Schema.org markup, knowledge graph entries)
- Cross-validation across multiple sources
Grokipedia contributes to that third factor. It provides one more reference point Google can use to validate entity attributes. But it's a contributing factor, not a magic trigger.
Of our three campaigns, none resulted in immediate knowledge panel creation. LoanOptions.ai now has improved knowledge panel eligibility, but Google hasn't granted one yet. That's honest reporting. We're not claiming miracles.
Why entities outperform keyword-heavy content
Here's the practical difference:
Keyword-focused approach: "LoanOptions.ai is a leading mortgage broker in Australia specialising in competitive loan rates and expert advice for homebuyers seeking trusted financial services."
Entity approach: Entity type: Financial Technology Company Industry: Mortgage Brokerage Founder: Julian Fayad Location: Australia Services: Mortgage comparison, broker matching, rate analysis
The second version maps directly to how knowledge graphs store information. AI systems can extract clear attributes, establish relationships, and position the entity within industry hierarchies. The keyword version offers fluffy marketing copy that's hard to parse.
Humans might prefer the first. Machines definitely prefer the second.
How co-occurrence networks strengthen entity recognition
One insight that held up across all three campaigns: entity clustering matters immensely.
When related entities appear together consistently (Julian Fayad + LoanOptions.ai + Australian fintech + mortgage brokerage), AI systems begin treating them as a semantic cluster. That clustering effect amplifies salience for all entities involved.
The Google Research paper on entity salience notes that proximity patterns influence ranking weight within semantic retrieval systems. [1] When entities co-occur in contexts repeatedly, confidence scores rise.
We observed this directly: creating links between Bushnote, LoanOptions.ai, and Julian Fayad on Grokipedia strengthened recognition for all three entities. Testing queries that mentioned one often surfaced the others in AI-generated context.
Network effects compound. That's not marketing fluff; it's how knowledge graphs function mechanically.
What the research actually says
Google Research (2014): Dunietz and Gillick's work on entity salience established that subject-position entities in factual statements receive higher prominence scores. This directly influenced how we built Grokipedia content: making our entities subjects of clear, declarative statements. [1]
Knowledge Graph Systems (2023): The Artificial Intelligence Review paper examines how entity disambiguation and relationship mapping improve machine reasoning. The key takeaway: ambiguous entities get filtered out. Clear entities with defined relationships get prioritised. [2]
GEO Research (2024): Aggarwal et al.'s paper demonstrated that citation formatting, source authority, and entity references significantly influence LLM answer generation. They tested interventions that increased visibility in AI-generated answers by up to 40%. [3]
Practical context: Search Engine Land's GEO guide translates this research into practitioner terms: AI-generated answers prioritise entities with presence across sources, cross-validated attributes, and semantic relationships. [5]
This isn't speculative. The research exists. The mechanisms are documented. What remains uncertain is how individual platforms weight these signals, and that's changing constantly.
Does data like this create knowledge panels?
Data like these doesn't cause knowledge panel creation. Google has never published the exact criteria, but we know from observation that knowledge panels depend on multiple factors:
- Entity notability (Wikipedia presence, media coverage, authoritative mentions)
- Search volume for the entity's name
- Data presence (Schema.org markup, knowledge graph entries)
- Cross-validation across multiple sources
Grokipedia contributes to that third factor. It provides one more reference point Google can use to validate entity attributes. But it's a contributing factor, not a magic trigger.
Of our three campaigns, none resulted in immediate knowledge panel creation. LoanOptions.ai now has improved knowledge panel eligibility, but Google hasn't granted one yet. That's honest reporting. We're not claiming miracles.
Why entities outperform keyword-heavy content
Here's the practical difference:
Keyword-focused approach: "LoanOptions.ai is a leading mortgage broker in Australia specialising in competitive loan rates and expert advice for homebuyers seeking trusted financial services."
Entity approach: Entity type: Financial Technology Company Industry: Mortgage Brokerage Founder: Julian Fayad Location: Australia Services: Mortgage comparison, broker matching, rate analysis
The second version maps directly to how knowledge graphs store information. AI systems can extract clear attributes, establish relationships, and position the entity within industry hierarchies. The keyword version offers fluffy marketing copy that's hard to parse.
Humans might prefer the first. Machines definitely prefer the second.
What we're still figuring out
We don't have all the answers. Here's what remains unclear:
Authority signals: How much weight does Google assign to Grokipedia pages compared to Wikipedia, official company sites, or news articles? We don't know.
Indexing speed: Some pages appeared in AI answers within weeks. Others took months. We haven't identified the pattern yet.
Durability: Do these visibility gains hold long-term, or do they require ongoing reinforcement? Too early to say.
Cross-platform effects: Does visibility in ChatGPT correlate with visibility in Google AI Overviews? Sometimes yes, sometimes no.
Attribution: When multiple tactics run simultaneously (Grokipedia + content + PR), isolating which drove specific outcomes is nearly impossible without controlled experiments.
This is frontier work. We're building patterns from observations, refining based on results, and staying honest about uncertainty.
Avoiding promotional bias in entity work
One critical principle: entity pages must remain factual. The moment you inject promotional language or subjective claims, you undermine machine trust. What works:
- "Bushnote provides semantic entity strategy and AEO consulting"
- "Julian Fayad founded LoanOptions.ai in 2018"
- "LoanOptions.ai operates in the Australian mortgage brokerage market"
What doesn't:
- "Bushnote is Australia's leading AEO agency" (subjective, unverifiable)
- "Julian Fayad is an ambitious fintech entrepreneur" (promotional tone)
- "LoanOptions.ai offers the best mortgage rates" (comparative claim without data)
AI systems prioritise neutral, verifiable statements. Promotional language reduces credibility scores, which directly impacts whether your entity gets referenced in generated answers.
Our Grokipedia pages stick religiously to factual declarations. It's not an exciting marketing copy, but it's effective for the intended purpose. How to think about entity strategy
Traditional SEO asked: "How do we rank for this keyword?" Entity strategy asks: "How do we ensure AI systems recognise us as a legitimate entity within our domain?" That shift demands different tactics:
- Schema.org markup on your website
- Consistent NAP (Name, Address, Phone) across directories
- Clear attribute definition on entity platforms like Grokipedia
- Relationship mapping to related entities
- Authority signals from reputable sources
It's less about manipulating algorithms and more about providing machine-readable clarity. When you make it easy for AI systems to understand who you are, what you do, and how you connect to your industry, visibility follows naturally.
What this means for Australian businesses
Australia's digital market is sophisticated but not saturated. That creates opportunity: early adopters of entity work and GEO tactics gain visibility before competition catches up.
We've seen this pattern before with traditional SEO. Companies that invested in Schema.org markup early (2010-2015) captured rich results before competitors understood the value. Entity strategy is the current equivalent.
Local businesses, professional services, and B2B companies can establish presence now, positioning for a future where AI-generated answers dominate discovery. Waiting until the tactic becomes mainstream means fighting entrenched competitors.
The tools exist today. Grokipedia is accessible. Schema.org markup is straightforward. Knowledge graph research is published openly. The barrier isn't access; it's understanding how to apply it strategically.
The bottom line on entity visibility
What we're confident about:
- AI-generated answers are replacing traditional search results for many queries
- Entity presence influences which organisations get referenced
- Knowledge graphs prioritise clear attributes, defined relationships, and cross-validated facts
- Early indicators from our campaigns suggest Grokipedia contributes to improved visibility
What we're still testing:
- How different platforms weight Grokipedia authority
- Optimal refresh cadence for entity pages
- Best practices for relationship mapping at scale
- Long-term durability of visibility gains
What we know for certain: sitting still means falling behind. The shift from keyword SEO to entity recognition isn't coming. It's here. The question isn't whether to adapt, but how quickly you can execute.
Bushnote's campaigns for LoanOptions.ai, Julian Fayad, and ourselves demonstrate that entity strategy produces measurable outcomes. Not every result is dramatic. Not every tactic succeeds immediately. But the direction is clear: entity visibility matters increasingly, and presence in these systems is the foundation.
TLDR
Bushnote built entity pages on Grokipedia for LoanOptions.ai (a fintech company), Julian Fayad (its founder), and Bushnote (our agency). Early signs suggest better visibility in AI-generated answers and stronger entity recognition in search systems. Proving direct causation is messy. This article shares what we observed, the research backing our approach, and where the gaps remain.
Key Takeaways
- AI systems now understand entities, not just keywords, making entity visibility crucial for brand recognition.
- Modern search relies on knowledge graphs, so structuring information as semantic triples is key for AI understanding.
- Grokipedia, an AI-generated encyclopedia, offers a new avenue for improving entity visibility in AI systems.
- Generative Engine Optimisation (GEO) is vital; entities must exist in underlying knowledge structures to be seen by AI.
- Creating Grokipedia entity pages can demonstrably improve brand search features and AI system mentions.
Citations
[1] Dunietz, J., & Gillick, D. (2014). A New Entity Salience Task with Millions of Training Examples. Google Research. https://research.google/pubs/a-new-entity-salience-task-with-millions-of-training-examples/
[2] Knowledge Graphs: Opportunities and Challenges. (2023). Artificial Intelligence Review. https://dl.acm.org/doi/10.1007/s10462-023-10465-9
[3] Aggarwal, P., et al. (2024). Generative Engine Optimization. Princeton University, Georgia Tech, IIT Delhi, Allen Institute for AI.
[4] Grokipedia. Wikipedia. https://en.wikipedia.org/wiki/Grokipedia
[5] What is Generative Engine Optimization (GEO)? Search Engine Land. https://searchengineland.com/what-is-generative-engine-optimization-geo-444418